决策树(Decision Tree)与随机森林(Random Forests)¶
作者:欧新宇(Xinyu OU)
本文档所展示的测试结果,均运行于:Intel Core i7-7700K CPU 4.2GHz
1. 决策树¶
1.1决策树的基本原理¶
决策树(Decision Tree) 是一种基本的分类和回归算法(本课程仅讨论决策树在分类中的应用)。决策树模型呈树形结构,在分类问题中,依据样本的特征对实例进行分类,是一种典型的if-then/else-then推导规则,从数学原理上理解,它也可以被认为是定义在特征空间与类别空间上的条件概率分布。
- 学习时: 利用训练数据,根据损失函数最小化的原则建立决策树模型;
- 预测时: 对新的数据,利用决策树模型进行分类。
决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的修剪。
下面给出一个利用决策树进行判定的图例,要求:根据一系列的属性特征输出特定的人物:

1.2决策树的构建¶
1. 载入数据库并进行数据预处理¶
以wine酒数据集为例,构建一个决策树模型
# 导入numpy计算库
import numpy as np
# 导入画图工具
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
# 导入tree树模型和数据集加载工具
from sklearn import tree
from sklearn import datasets
# 导入数据拆分工具
from sklearn.model_selection import train_test_split
wine = datasets.load_wine()
# 设置X, y的值。此处为了便于可视化,仅选取前两个特征
X = wine.data[:, :2]
#X = wine.data
y = wine.target
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y)
2. 配置决策树,并拟合训练集¶
# 设置决策树的分类器的最大深度为 1
clf = tree.DecisionTreeClassifier(max_depth = 1)
# 拟合训练数据集
clf.fit(X_train, y_train)
3. 可视化分类器结果¶
# 定义图像中分区的颜色和散点的颜色
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
# 分别用样本的两个特征值创建图像的横轴和纵轴
x_min, x_max = X_train[:, 0].min() - 1, X_train[:, 0].max() + 1
y_min, y_max = X_train[:, 1].min() - 1, X_train[:, 1].max() + 1
# 设置特征轴的尺度的粒度
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# 给每个分类中的样本分配不同的颜色
Z = Z.reshape(xx.shape)
plt.figure(dpi = 100)
plt.rcParams['font.sans-serif'] = [u'Microsoft YaHei']
plt.pcolormesh(xx, yy, Z, cmap = cmap_light)
# 用散点把样本表示出来
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = cmap_bold, edgecolor = 'k', s = 20)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("分类器: 决策树(max_depth = 1)")
plt.show()
【知识点】[ravel()函数、flatten()函数和squeeze()函数](functions/numpy.ravel_flatten_squeeze.ipynb)
4. 对比不同深度决策树的分类性能¶
- 深度max_depth = 3 时
import matplotlib.pyplot as plt3
# 设置决策树的分类器的最大深度,并拟合训练集
clf3 = tree.DecisionTreeClassifier(max_depth = 3)
clf3.fit(X_train, y_train)
Z3 = clf3.predict(np.c_[xx.ravel(), yy.ravel()])
# 给每个分类中的样本分配不同的颜色
Z3 = Z3.reshape(xx.shape)
plt3.figure(dpi = 100)
plt.rcParams['font.sans-serif'] = [u'Microsoft YaHei']
plt3.pcolormesh(xx, yy, Z3, cmap = cmap_light)
# 用散点把样本表示出来
plt3.scatter(X[:, 0], X[:, 1], c = y, cmap = cmap_bold, edgecolor = 'k', s = 20)
plt3.xlim(xx.min(), xx.max())
plt3.ylim(yy.min(), yy.max())
plt3.title("分类器: 决策树(max_depth = 3)")
plt3.show()

- 深度max_depth = 5 时
import matplotlib.pyplot as plt5
# 设置决策树的分类器的最大深度,并拟合训练集
clf5 = tree.DecisionTreeClassifier(max_depth = 5)
clf5.fit(X_train, y_train)
Z5 = clf5.predict(np.c_[xx.ravel(), yy.ravel()])
# 给每个分类中的样本分配不同的颜色
Z5 = Z5.reshape(xx.shape)
plt5.figure(dpi = 100)
plt.rcParams['font.sans-serif'] = [u'Microsoft YaHei']
plt5.pcolormesh(xx, yy, Z5, cmap = cmap_light)
# 用散点把样本表示出来
plt5.scatter(X[:, 0], X[:, 1], c = y, cmap = cmap_bold, edgecolor = 'k', s = 20)
plt5.xlim(xx.min(), xx.max())
plt5.ylim(yy.min(), yy.max())
plt5.title("分类器: 决策树(max_depth = 5)")
plt5.show()
5. 对模型进行评估¶
分别评估三个模型在训练集、测试集上的准确率
# 输出模型评分,即正确率
score_train = clf.score(X_train, y_train)
score3_train = clf3.score(X_train, y_train)
score5_train = clf5.score(X_train, y_train)
score_test = clf.score(X_test, y_test)
score3_test = clf3.score(X_test, y_test)
score5_test = clf5.score(X_test, y_test)
print("模型一(树深 = 1):训练集准确率:{0:.3f},测试集准确率:{1:.3f}".format(score_train, score_test))
print("模型二(树深 = 3):训练集准确率:{0:.3f},测试集准确率:{1:.3f}".format(score3_train, score3_test))
print("模型三(树深 = 5):训练集准确率:{0:.3f},测试集准确率:{1:.3f}".format(score5_train, score5_test))
由结果可以得到以下结论:
- 随着决策树的深度增加,模型的性能得到了一定的提升(在一定范围内);
- 深度增加到5时,模型出现了过拟合现象。即:训练集性能持续提高,测试集性能出现了降低。
下面请大家尝试,在Wine酒数据集上使用**决策树**对所有特征进行建模,并给出树深分别为{1, 3, 5}时的模型准确率。
1.3 决策树的优缺点¶
- 优点:计算复杂度低,分类速度快,模型易于理解、可读性高,对中间值的缺失不敏感
- 缺点:可能会产生过度匹配问题
- 适用数据类型:数值型和标称型
1.4 决策树的工作过程的可视化¶
(不要求掌握该方法,只需要能理解即可)
Graphviz (Graph Visualization Software) 是一个由AT&T实验室启动的开源工具包,可以用于绘制各种流程图和结构图。它依赖于DOT描述语言,DOT是一种图形描述语言,具有简单易学的特点。
对于程序员来说,关于Graphviz有一句很著名的话:So in short, if you are a programmer, it is born for you。
- 安装graphviz
- 官网下载 graphviz, 并进行安装
- 添加系统变量,将"./Graphviz2.38" 和 "./Graphviz2.38/bin"添加到环境变量;将"./Graphviz2.38/bin/dot.exe"添加到系统变量。
- pip install graphviz 或 conda install graphviz
- 绘制流程图
# 载入graphviz绘图工具包
import graphviz
# 导入决策树中输出graphiviz的接口
from sklearn.tree import export_graphviz
import os
filePath = os.path.join(os.getcwd() + '\\tmp\\')
fileName = os.path.join(filePath + 'Wine.dot')
#选择分类模型
export_graphviz(clf3, out_file = fileName, \
class_names = wine.target_names, \
feature_names = wine.feature_names[:2], \
impurity = False, filled = True)
# 打开dot文件
with open(fileName) as f:
dot_graph = f.read()
# 显示dot文件中的图形
graphviz.Source(dot_graph)
2.随机森林¶
决策树是一种比较简单的算法,但是很容易出现过拟合问题(前面我们已经看到了这个现象),一个比较好的解决办法是,将更多的树扩展成森林————随机森林。
随机森林是一种有监督学习算法,它是以决策树为基学习器的集成学习算法。随机森林非常简单,易于实现,计算开销也很小,但是它在分类和回归上表现出非常惊人的性能,因此,随机森林被誉为“代表集成学习技术水平的方法”。
**【知识点】**集成学习(ensemble learning): 集成学习是一种非常有效的学习方法,它致力于整合多个弱分类器为强分类器,从而实现整体性能的提升。最常见的算法有:bootstrape, boosting和bagging等。
中国自古就有:三个臭皮匠顶个诸葛亮,一箭易折十箭难折,千里之堤溃于蚁穴。有兴趣的同学可以百度一下*集成学习*。
2.1 随机森林的基本概念¶
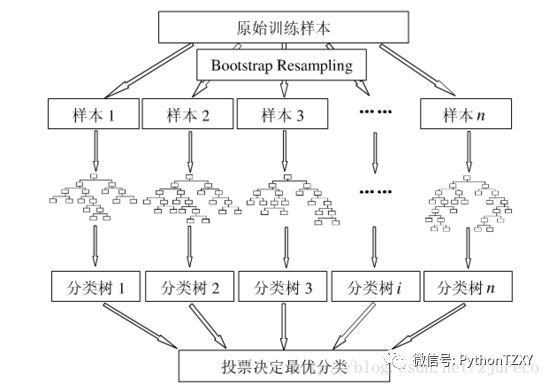
在机器学习中,随机森林是一个包含多个决策树的分类器,其输出的类别是由每棵树的输出进行联合判决。随机森林最初是由Leo Breiman和Adele Cutler提出,并以"Random Forests"作为商标,而该术语则是由贝尔实验室的Tin Kam Ho所提出的随机决策森林(random decision forests)而来。
以下给出,随机森林的算法过程:
1. 假设用 N 来表示训练样本的个数,M 表示特征的数目;
2. 输入特征数目 m,用于确定决策树上一个节点的决策结果;其中 m 应远小于 M;
3. 从 N 个训练样本中以(放回)抽样的方式,取样 N 次,形成一个训练集(即 bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差;
4. 对于每一个节点,随机选择 m个特征,决策树上每个节点的决定都是基于这些特征确定的。根据这 m个特征,计算其最佳的分裂方式。
5. 每棵树都会完整成长而不会剪枝,这有可能在建完一棵正常树状分类器后会被采用。
2.2 随机森林的构建¶
1. 载入Wine酒数据集并进行预处理¶
from sklearn import datasets
from sklearn.model_selection import train_test_split
# 导入随机森林模型
from sklearn.ensemble import RandomForestClassifier
wine = datasets.load_wine()
X = wine.data[:, :2] # 为便于可视化仍然仅使用前两个特征
y = wine.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
2. 模型训练¶
# 设定随机森林中树的数量,此处 = 6
forest = RandomForestClassifier(n_estimators = 6, random_state = 3, n_jobs = -1)
forest.fit(X_train, y_train)
关于随机森林参数的一些解释:
- bootstrap(True,False): 该参数用于设定是否启用bootstrap算法,即“有放回抽样”,准确地说叫“重抽样”。它允许每次生成的数据集都从一个统一的数据集中进行采样,这样一方面可以保证总样本数不变,另一方面也确保了采样的随机性。Bootstrap是现代统计学较为流行的一种统计方法,在小样本数据集中使用效果很好,通过方差的估计可以构造置信区间等,其运用范围得到进一步延伸。同时,对于未知样本分布的数据中,bootstrap也是最有用的,它可以用来估计真实的分布。
- class_weight: 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多,导致训练的决策树过于偏向这些类别。其中最严重的现象之一就是"
长尾效应"。典型值为“balanced”和“None”,前者算法会自己计算权重,样本量少的类别所对应的样本权重会高;后者,则使用等权重。当数据集样本类别分布没有明显偏向时,可以不管这个参数,保持默认的"None"。 - max_features: 该参数用于控制特征最大数量,典型值较多,包括int, $Log_2 N$,$sqrt{(N)}$, 浮点百分比等。当特征数较少(<50)可以不考虑该参数。
- max_leaf_nodes(int, None): 强制剪枝参数,用于设置最大的叶子节点数,默认值为None,表示不限制叶子节点数。该参数通过强制剪枝实现生成的森林具有独特性,以实现样本预测的多样性。设置合理的max_leaf_nodes可以有效地改进过拟合和欠拟合问题。如果特征不多,可以不考虑该值;当特征较多时,通过限制叶子数可以获得最优森林,一般可以通过交叉验证来选择该参数的最优值。同样,当特征数较多的时候(例如>200),可以考虑设置该参数。
- n_estimators(int): 这是一个非常重要的参数。用于设置随机森林中决策树的数量。对于回归分析,随机森林会把所有决策树预测的值取平均数进行输出;对于分类,随机森林会通过“投票”(求每棵树的概率的平均值)来预测样本的类别。
- n_jobs(int, -1): 用于设置并行处理的CPU核心数,典型值为int型,表示使用多少个核心,当n_jobs = -1时,表示使用全部核心。在进行较大数据集的建模时,这将大幅提高训练的速度。不幸的是,scikit-learn工具包不支持GPU并行运算,只支持CPU的多核心并行。
- random_state: 该参数和其他算法中的含义一样,用于控制随机种子,以产生固化不变的"随机值"。
3. 模型评估¶
score_train = forest.score(X_train, y_train)
score_test = forest.score(X_test, y_test)
print("随机森林:\n 训练集准确率:{0:.3f},测试集准确率:{1:.3f}".format(score_train, score_test))
4. 可视化分类结果¶
# 定义图像中分区的颜色和散点的颜色
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
# 分别用样本的两个特征值创建图像的横轴和纵轴
x_min, x_max = X_train[:, 0].min() - 1, X_train[:, 0].max() + 1
y_min, y_max = X_train[:, 1].min() - 1, X_train[:, 1].max() + 1
# 设置特征轴的尺度的粒度
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))
Z = forest.predict(np.c_[xx.ravel(), yy.ravel()])
# 给每个分类中的样本分配不同的颜色
Z = Z.reshape(xx.shape)
plt.figure(dpi = 100)
plt.rcParams['font.sans-serif'] = [u'Microsoft YaHei']
plt.pcolormesh(xx, yy, Z, cmap = cmap_light)
# 用散点把样本表示出来
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = cmap_bold, edgecolor = 'k', s = 20)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("分类器:随机森林")
plt.show()

从结果看,随机森林获得的结果要更加细腻。有兴趣的同学,可以尝试调整一下参数n_estimator和random_state,看看是否能获得更好的预测结果。
2.3 随机森林的优缺点¶
- 优点
- 由于采用了集成算法,本身精度比大多数单个算法要好,所以准确性高
- 在测试集上表现良好,由于两个随机性的引入,使得随机森林不容易陷入过拟合(样本随机,特征随机)
- 在工业上,由于两个随机性的引入,使得随机森林具有一定的抗噪声能力,对比其他算法具有一定优势
- 由于树的组合,使得随机森林可以处理非线性数据,本身属于非线性分类(拟合)模型
- 它能够处理很高维度(feature很多)的数据,并且不用做特征选择,对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化
- 训练速度快,可以运用在大规模数据集上
- 在训练过程中,能够检测到feature间的互相影响,且可以得出feature的重要性,具有一定参考意义
- 由于每棵树可以独立、同时生成,容易做成并行化方法
- 由于实现简单、精度高、抗过拟合能力强,当面对非线性数据时,适于作为基准模型(Baseline)
- 缺点
- 当随机森林中的决策树个数很多时,训练时需要的空间和时间会比较大
- 随机森林中还有许多不好解释的地方,有点算是黑盒模型
- 在某些噪音比较大的样本集上,模型容易陷入过拟合
3.实例分析——基于Adult数据集的相亲问题¶
3.1 载入数据集¶
- 下载数据集:
下载地址:http://archive.ics.uci.edu/ml/machine-learning-databases/adult
- adult.names 数据集的基本信息,文本文档(可改名)
- adult.data 训练集数据,下载后改名为:adult_train.csv
- adult.test 测试集数据,下载后改名为:adult_test.csv
- 载入数据集
由于该数据集并没有在数据表中给出特征的描述,为了方便理解,我们需要手动添加特征的title(英文原版描述可以在adult.names文件中找到)。
import pandas as pd
data = pd.read_csv('../Datasets/adult/adult_train.csv', header=None, index_col=False,
names=['年龄','单位性质','权重','学历','受教育时长',
'婚姻状况','职业','家庭情况','种族','性别',
'资产所得','资产损失','周工作时长','原籍',
'收入'])
# 使用display()函数显示部分数据,以供预览
# .head()方法实现只显示前 5 行
# display(data.head())
#为了方便展示,可以选取其中一部分特征(9个)进行显示
data_lite = data[['年龄','单位性质','学历','婚姻状况','种族','性别','周工作时长', '职业','收入']]
display(data_lite.head())
3.2 数据预处理¶
从原始数据可以看到绝大多数特征都是字符串形式,这是无法进行使用和分析的。我们有两种方法对数据进行预处理:
- 将特征的每种取值都抽象成一种,并用布尔类型进行表示。例如,特征"学历"改为多个特征,包括"学历_Bachelors","学历_Masters", "学历_Doctorate",每个特征的分别用0和1来表示,是否满足该条件。该方法被称为"one-hot编码(独热编码)".
- 将特征的每种取值赋一个值。例如,特征"学历"将包含多个值,0表示Bachelors, 1表示Masters, 2表示Doctorate
此处,为了简便,我门将采用第一种(one-hot)方法,并使用pandas数据集的get_dummies()方法来实现。该方法为现有数据特征添加虚拟变量,将一个$n$类特征变量扩展为$n$个one-hot特征变量。
data_dummies = pd.get_dummies(data_lite)
print('样本原始特征:\n',list(data_lite.columns),'\n')
print('虚拟变量特征:\n',list(data_dummies.columns))
display(data_dummies.head())
从上面的图表中可以看出,原来的 9 个特征已经被扩展为 58 个,原因就是get_dummies()函数将原来的多类特征进行了one-hot扩展。下面,我们将新的特征分配给特征向量X和分类标签y。
此处,我们将"收入"定义为标签 y,如果"收入_>50K",则$y = 1$; 否则 $y = 0$。
features = data_dummies.loc[:,'年龄':'职业_ Transport-moving']
X = features.values
y = data_dummies['收入_ >50K'].values
print("特征X的形态:{0}, 标签y的形态:{1}".format(X.shape, y.shape))
【知识点】[pandas中的loc()函数和iloc()函数](functions/loc_iloc.ipynb)
从数据结果来看,获取到的特征 X,共有32561个样本,每个样本包含56种特征。
3.3 使用决策树建模并进行评分¶
# 拆分数据集,并用训练数据拟合决策树模型
from sklearn.model_selection import train_test_split
from sklearn import tree
X_train,X_test,y_train,y_test = train_test_split(X, y, random_state=0)
dt = tree.DecisionTreeClassifier(max_depth = 5)
dt.fit(X_train,y_train)
print('模型得分:{:.2f}'.format(dt.score(X_test,y_test)))
值得注意的是,此处建模所用的训练集和测试集均是由原有的训练集进行拆分获得。
3.4 利用给定的数据进行预测¶
给定一个新样本,我们用模型预测一下他的收入情况。
- 给定特征:年龄27,周工作时长35,单位性质为国家机关(单位性质 State-gov = 1),学历为博士(学历 Doctorate = 1),性别男(性别 Male = 1),未婚(婚姻状况 Never-married = 1),亚洲人(种族 Other = 1),职业是教授(职业 Prof-specialty = 1);其他特征值 = 0
- 收入情况:如果收入>=50K,则标签= 1;如果收入<=50K, 则标签 = 0
['年龄', '周工作时长', '单位性质 ?', '单位性质 Federal-gov', '单位性质 Local-gov',
'单位性质 Never-worked', '单位性质 Private', '单位性质 Self-emp-inc', '单位性质 Self-emp-not-inc', **'单位性质 State-gov',
'单位性质 Without-pay', '学历 10th', '学历 11th', '学历 12th', '学历 1st-4th',
'学历 5th-6th', '学历 7th-8th', '学历 9th', '学历 Assoc-acdm', '学历 Assoc-voc',
'学历_ Bachelors', '学历 Doctorate'**, '学历 HS-grad', '学历 Masters', '学历 Preschool',
'学历 Prof-school', '学历 Some-college', '婚姻状况 Divorced', '婚姻状况 Married-AF-spouse', '婚姻状况 Married-civ-spouse',
'婚姻状况 Married-spouse-absent', '婚姻状况_ Never-married', '婚姻状况 Separated', '婚姻状况 Widowed', '种族 Amer-Indian-Eskimo',
'种族 Asian-Pac-Islander', '种族 Black', **'种族 Other', '种族 White', '性别 Female',
'性别 Male'**, '职业 ?', '职业 Adm-clerical', '职业 Armed-Forces', '职业 Craft-repair',
'职业 Exec-managerial', '职业 Farming-fishing', '职业 Handlers-cleaners', '职业 Machine-op-inspct', '职业 Other-service',
'职业 Priv-house-serv', **'职业 Prof-specialty'**, '职业 Protective-serv', '职业 Sales', '职业 Tech-support',
'职业 Transport-moving',
'收入 <=50K', '收入 >50K']
Mr_Right =[[27, 35, 0, 0, 0, 0, 0, 0, 0, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 0, 1, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0]]
pred = dt.predict(Mr_Right)
if dt == 1:
print("大胆去追求真爱吧,这哥们月薪过5万了!")
else:
print("不用去了,不满足你的要求")
值得注意的是,Adult虽然是真实数据集,但是其数据仅仅是美国的特定人群,因此输出结果仅供娱乐!**切勿当真!**
3.5 更完整的建模和预测¶
在上面的例子中,我们对数据集进行了一定的简化,下面我们将展现如何更完整地利用数据集并进行分析,具体改进包括:
- 同时使用原始的训练集(adult_train)和测试集(adult_test)
- 使用所有特征
- 同时使用决策树和随机森林算法进行建模
import pandas as pd
train = pd.read_csv('../Datasets/adult/adult_train.csv', header=None, index_col=False,
names=['年龄','单位性质','权重','学历','受教育时长',
'婚姻状况','职业','家庭情况','种族','性别',
'资产所得','资产损失','周工作时长','原籍',
'收入'])
test = pd.read_csv('../Datasets/adult/adult_test.csv', header=None, index_col=False,
names=['年龄','单位性质','权重','学历','受教育时长',
'婚姻状况','职业','家庭情况','种族','性别',
'资产所得','资产损失','周工作时长','原籍',
'收入'])
test = test.loc[1:]
print("train: {}, test: {}".format(train.shape, test.shape))
train_dummies = pd.get_dummies(train)
test_dummies = pd.get_dummies(test)
print("train的形态为: {}, test的形态为: {}".format(train_dummies.shape, test_dummies.shape))
从训练集和测试集的形态来看,它们具有不同的特征空间,因此无法用统一的标准进行衡量,因此,我们需要先将两个数据集进行合并,扩展特征后,再进行拆分。
此处,我们可以使用pandas.concat()函数实现合并。
data = pd.concat([train,test],ignore_index=True, axis=0) # axis = 0表示在纵轴上进行合并; axis = 1 表示在横轴上进行合并。
data_dummies = pd.get_dummies(data)
print("data_dumies的形态为: {}".format(data_dummies.shape))
在进行特征one-hot扩展之后,我们可以再次对样本进行拆分,拆分时可以使用原始样本的大小作为索引。
train_dummies = data_dummies.loc[0:train.shape[0] - 1]
test_dummies = data_dummies.loc[train.shape[0]:]
print("train的形态为: {}, test的形态为: {}".format(train_dummies.shape, test_dummies.shape))
此处,我们将除了收入以外的所有特征作为样本的特征,以"收入_ >50K"作为判别目标。
即,我们的目标是通过对所有特征的分析来获取收入的预测。
X_train = train_dummies.loc[:, '权重':'原籍_ Yugoslavia'].values
y_train = train_dummies['收入_ >50K'].values
X_test = test_dummies.loc[:, '权重':'原籍_ Yugoslavia'].values
y_test = test_dummies['收入_ >50K'].values
- 使用决策树和随机森林进行建模
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
dt = tree.DecisionTreeClassifier(max_depth = 5)
dt.fit(X_train, y_train)
forest = RandomForestClassifier(n_estimators = 6, random_state = 3, n_jobs = -1)
forest.fit(X_train, y_train)
print('决策树模型: 训练集得分: {0:.3f},测试集得分: {1:.3f}'.format(dt.score(X_train,y_train), dt.score(X_test,y_test)))
print('随机森林模型: 训练集得分: {0:.3f},测试集得分: {1:.3f}'.format(forest.score(X_train,y_train), forest.score(X_test,y_test)))
3.6 超参数搜索¶
从上面的结果看,随机森林有较严重的过拟合问题,理论上有一定的改进空间,下面我们尝试对决策树和随机森林都进行超参数搜索,看看是否能进一步提高它们的性能。
- 对于决策树,我们遍历树的深度,设 max_depth = [1 : 100]
- 对于随机森林,我们遍历森林的规模,设 n_estimators = [1 : 100]
然后,我们将不同参数下的评分输出成图。
import numpy as np
n = 100
scores = np.zeros([4, n]) #第1-4列分别为:score_train_dt,score_test_dt,score_train_rf,score_test_rf
num = np.arange(0, n)
for i in num:
n = i + 1
# 利用当行刷新方法显示正在计算的模型
print("\r 正在计算第{}/{}个模型,请稍等...".format(n, num.shape[0]), end="")
dt = tree.DecisionTreeClassifier(max_depth = n)
dt.fit(X_train, y_train)
rf = RandomForestClassifier(n_estimators = n, random_state = 3, n_jobs = -1)
rf.fit(X_train, y_train)
scores[0, i] = dt.score(X_train, y_train)
scores[1, i] = dt.score(X_test, y_test)
scores[2, i] = rf.score(X_train, y_train)
scores[3, i] = rf.score(X_test, y_test)
if i == num.shape[0] - 1:
print("计算完毕!")
利用输出的分数矩阵绘制"参数敏感"性能曲线图。参数敏感曲线通常用来进行参数选择,当参数稳定且达到峰值的时候就是参数的最优值。
import matplotlib.pyplot as plt
plt.figure(dpi=120)
plt.plot(num, scores[0,:], label="DecisionTree_Train")
plt.plot(num, scores[1,:], label="DecisionTree_Test")
plt.plot(num, scores[2,:], label="ForestClassifier_Train")
plt.plot(num, scores[3,:], label="ForestClassifier_Test")
plt.legend()
plt.show()

从结果来看,决策树和随机森林都出现了过拟合的现象,并且在训练集上的结果基本一致,这说明训练样本过于简单,不具备多样性。
在测试集上,随机森林比决策树要更好一些。有趣的是,决策树的性能持续下降最终收敛,而随机森林的性能开始振荡严重,但最终也收敛了。
但这不是说决策树在深度较浅的时候就一定好,因为性能的衡量不仅仅包括score,还包括召回率、ROC、AUC曲线等。
此处主要是用来演示(让大家学会)如何使用性能曲线来选择超参数。